
Elasticsearch產品使用心得分享

Elasticsearch產品使用心得分享
它的設置非常簡單,只要在各種伺服器上安裝Filebeat、Metricbeat、Auditbeat和Packetbeat,然後統整報告給Elasticsearch數據庫。
以下是我在Elasticsearch + Beats的使用心得&經驗分享給各位。
Filebeat和Metricbeat擁有自己的模組。這些是位於 /etc/{metric,file}beat/modules.d/中的特定服務的配置文件。雖然可以在主要配置文件中為Filebeat或Metricbeat執行特定服務的配置,但您也可以使用像是 filebeat modules enable system 之類的方法輕鬆啟用/關閉這些模組。
啟用這個方法(.yml文件),主要配置文件可以變得十分簡潔。
例如:
# cat /etc/filebeat/filebeat.yml
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.elasticsearch:
hosts: ["127.0.0.1:9200"]
若要查看當前為Filebeat啟用了哪些模組,可以使用指令 filebeat modules list:
# filebeat modules list Enabled: mysql nginx system Disabled: apache2 auditd icinga kafka logstash postgresql redis traefik
一個.yml檔看起來應該如下所示
# cat /etc/filebeat/modules.d/system.yml - module: system # Syslog syslog: enabled: true # Set custom paths for the log files. If left empty, # Filebeat will choose the paths depending on your OS. #var.paths: # Convert the timestamp to UTC. Requires Elasticsearch >= 6.1. #convert_timezone: false # Authorization logs auth: enabled: true # Set custom paths for the log files. If left empty, # Filebeat will choose the paths depending on your OS. #var.paths: # Convert the timestamp to UTC. Requires Elasticsearch >= 6.1. #convert_timezone: false
Elastic為Metricbeat和Filebeat模組提供了良好的說明文件。據我所知,Packetbeat和Auditbeat並沒有像Filebeat和Metricbeat那樣運用模組。
在我的特殊設置中,Packetbeat和Auditbeat(取決於您的設置)會產生海量的訊息。 特別是Packetbeat NFS的紀錄,會形成一個反饋循環(feedback loop)。運行Elasticsearch的虛擬機器存取數據庫時,實際上需要透過主機的作業系統去NFS上讀取資料,因此會產生新的(不必要的)NFS使用紀錄,增加系統負擔。
另外,啟用Auditbeat所有“內核”部分的內容也會產生大量的數據(至少是我碰到的狀況)。如果你有需要,或者有足夠的儲存空間/頻寬,你可以考慮紀錄下所有數據,然而我缺乏頻寬,也並不需要,因此沒有紀錄所有數據。由於我所有的網路伺服器在大部分時間都是空閒的,因此啟用Filebeat並沒有對我的伺服器造成太大影響。如果我的伺服器當時正好在營運並使用大量的流量,那可能會產生很不同的結果。
另外,Filebeat並不像Packetbeat那樣的"健談"(除非禁用NFS)。Metricbeat也生成相當數量的數據。由於我想比較Metricbeat的系統監視與Zabbix的系統監視不同處,所以我只做了一些小改動(取消內核,硬碟跟socket的註解):
# cat /etc/metricbeat/modules.d/system.yml - module: system period: 10s metricsets: - cpu - load - memory - network - process - process_summary - core - diskio - socket processes: ['.*'] process.include_top_n: by_cpu: 10 # include top 5 processes by CPU by_memory: 10 # include top 5 processes by memory - module: system period: 1m metricsets: - filesystem - fsstat processors: - drop_event.when.regexp: system.filesystem.mount_point: '^/(sys|cgroup|proc|dev|etc|host|lib)($|/)' - module: system period: 15m metricsets: - uptime
Metricbeat系統模塊+ Filebeat系統模塊的功能大約等於Zabbix Linux模板。
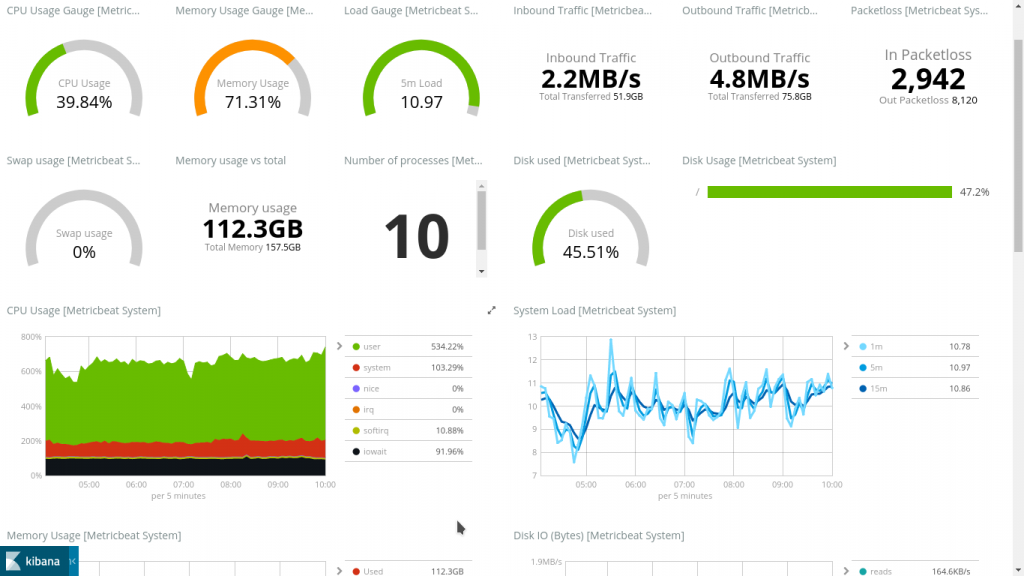
Elasticsearch會霸占您的I/O使用量!至少這是現在發生在我身上的事情。我當然可以減少記錄的項目以減輕I/O使用量,但就目前的iowait狀況而言,我們可從下圖看出端倪:
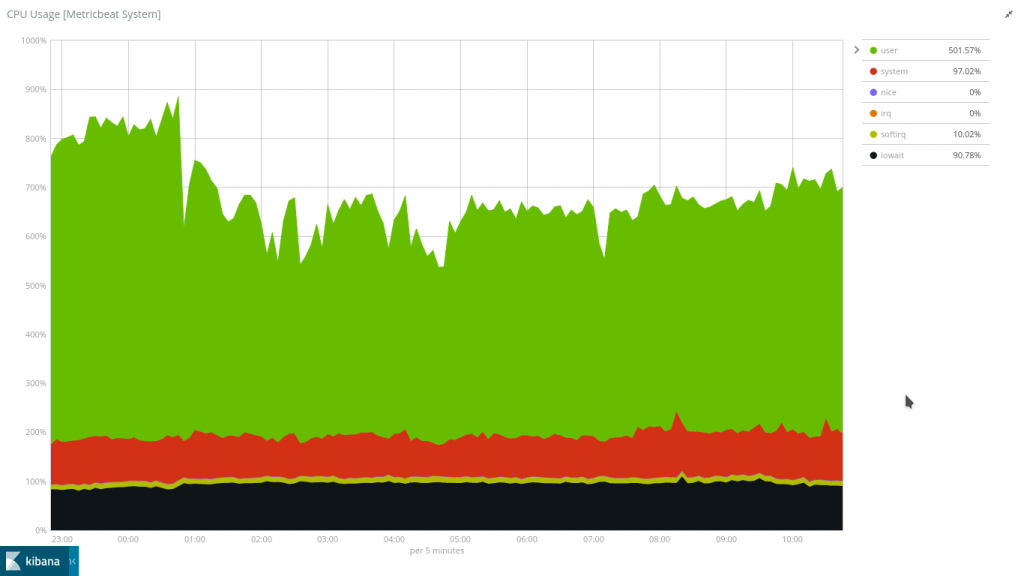
我認為他們為iowait選擇了一個很好的預設顏色,就像通過柏油路一樣,因為此時我的存儲速度極度緩慢。如果你會將大量數據轉儲到Elasticsearch數據庫中,並同時檢索大量數據,在這種情況下使用一般硬碟並非是一個理想的選擇。不理想到讓我認真考慮,像這種需要快速I/O的情況下,是否使用兩個固態硬碟來替換原本的ZFS log鏡像驅動器。雖然我認為這並非必要之舉,但是如果我想用目前的設置來看一個比12小時更長的時間,就會因為讀取時間過長無法執行。在這點上Zabbix就贏了。雖然我確信有可能讓Zabbix記錄一大堆訊息,但這些訊息會自行消滅,我從來沒有這樣做過。 讓Elasticsearch來做這點相對容易多了。與我在工作機上用SSD創建類似的設置比較(更少的主機記錄,但確實啟用了內核):
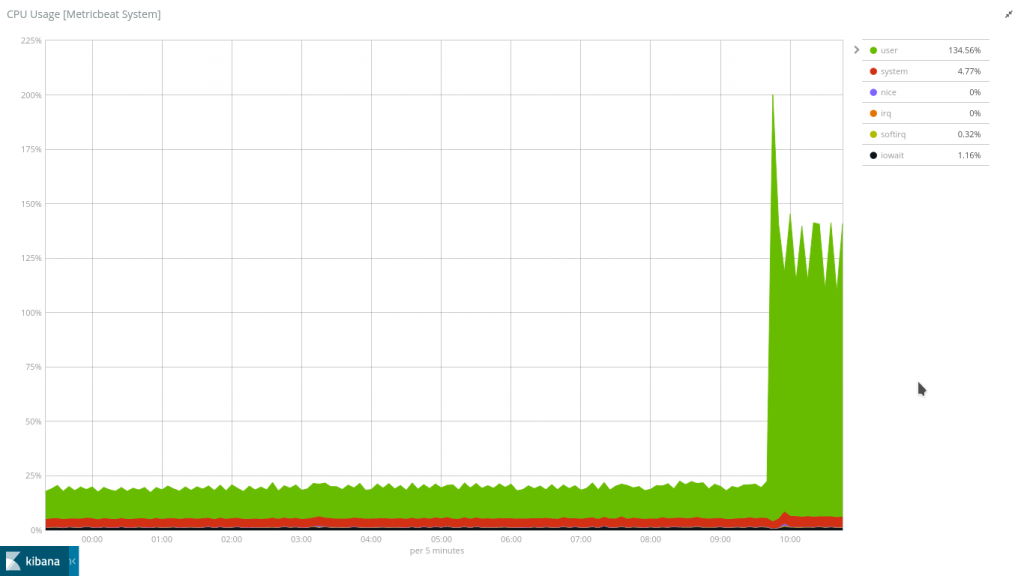
SSD上的iowait與我在Dallas的一般硬盤相比少了非常多。我將繼續研究如何由設定中"榨出"更多的效能。
將主機的時區設置為UTC,以避免在查看Kibana中的事件時出現的問題。我曾碰過,因為時間差被加了兩次,導致出現了“事件發生時間在未來"的問題。在將所有伺服器設置為UTC並且重新啟動後,一切運作正常。
以下為我的實作心得:
利用Elasticsearch可以記錄大量的系統行為,分析後可以得到很多關於你的系統/網路行為有用的相關資訊,但是你最好有足夠儲存速度和容量的儲存設備來看到/存取它們。如果沒有足夠的儲存設備,也可以通過減少紀錄項目或頻率(改變每個*beat的循環速率)。 Zabbix能提供通知和警告空間即將不足的功能。具我所知,Elastic這個功能需要付費訂閱X-Pack。
相關文章: 如何使用Zabbix Alert Scripts





我要留言